

Building on a momentous shift in how organisations treat data, Snowpark brings a developer-first, in-database compute model that understands data priorities, adapts to enterprise environments, and gives teams greater control at every step of the data lifecycle. The framework orchestrates data processing, feature engineering, and model scoring where the data resides eliminating costly movement, simplifying governance, and enabling faster time-to-value for analytics and machine learning initiatives across global markets including the USA and UAE.
What Snowpark is — the simple definition
Snowpark is Snowflake’s developer framework and set of client libraries that allow engineers and data scientists to write data pipelines, user-defined functions, and machine-learning workflows using familiar languages such as Python, Java, and Scala, and execute them directly within Snowflake’s execution engine.
In simple terms, Snowpark brings the code to the data. Instead of extracting large volumes of data into external processing engines, Snowpark enables computation to occur inside the data platform itself. This approach reduces architectural complexity, strengthens governance, and allows organizations to take full advantage of Snowflake’s elastic compute model.
Why Snowpark matters now
Several structural shifts in enterprise data strategy make Snowpark particularly relevant today.
First, data gravity has become a dominant concern. As data volumes grow and regulatory requirements tighten, organizations are increasingly reluctant to move sensitive or high-value datasets across multiple platforms. Processing data where it already lives reduces exposure and simplifies compliance.
Second, developer expectations have evolved. Data engineers and analytics teams increasingly favor language-native development over proprietary, tool-specific workflows. Snowpark meets teams where they already work by offering familiar DataFrame-style APIs.
Third, the data platform landscape is converging. Warehousing, data engineering, and machine learning are no longer separate domains. Snowpark reflects this convergence by extending Snowflake beyond analytics into transformation and ML workloads, reshaping how organizations think about their data stacks.
Where organisations use Snowpark
Snowpark is used across multiple teams and operational contexts within modern data organizations.
Data engineering teams use Snowpark to build scalable ELT pipelines that are orchestrated directly within Snowflake.
Feature engineering teams leverage Snowpark to create model-ready features using governed, up-to-date data.
Machine learning teams use Snowpark for batch and near-real-time model scoring without exporting data to separate serving environments. This approach keeps pipelines simpler, more secure, and easier to govern.
Product and analytics teams use Snowpark to build internal data applications that require logic-driven processing, strong governance, and rapid iteration.
In regulated industries, Snowpark supports compliance-sensitive workflows by minimizing data duplication and maintaining a single source of truth.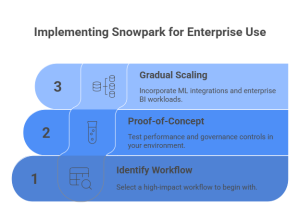
Core capabilities and technical highlights
Snowpark offers a combination of technical capabilities designed for enterprise scale.
It provides official libraries for Python, Java, and Scala, enabling developers to write transformations using familiar constructs. Workloads execute within Snowflake’s managed compute environment, benefiting from built-in isolation, security, and elasticity.
Snowpark integrates seamlessly with core Snowflake features such as task scheduling, change data capture, staged ingestion, and external function calls. This allows teams to design end-to-end pipelines without leaving the Snowflake ecosystem.
With the introduction of Snowpark ML and related machine-learning capabilities, organizations can increasingly manage feature engineering, training workflows, and model lifecycle activities within a unified data platform.
Competitive landscape and positioning
Snowpark competes most directly with Spark-based lakehouse platforms and cloud-native data processing services.
Spark-centric platforms are often preferred for large-scale distributed training and advanced machine-learning experimentation. Cloud-native services may be attractive for organizations deeply aligned with a single hyperscaler.
Snowpark’s differentiation lies in operational simplicity, governance, and consolidation. For organizations already using Snowflake as a central data platform, Snowpark reduces the need to manage parallel processing environments while maintaining strong performance for a broad class of analytics and transformation workloads.
Strengths, trade-offs, and practical limits
Aspect | Strengths | Trade-offs | Limits / Considerations |
Data movement | Processing happens where data resides, minimizing data movement and reducing risk | Strong dependence on in-platform execution | Less suitable if data must frequently move across multiple platforms |
Architecture | Simplified architecture with fewer external processing layers | Platform-centric design | Architectural flexibility is reduced outside the Snowflake ecosystem |
Developer experience | Familiar language-native APIs (Python, Java, Scala) accelerate adoption | Optimized for Snowflake-specific APIs | Portability to non-Snowflake environments may require refactoring |
Operational overhead | Infrastructure provisioning, scaling, and isolation are fully managed | Limited control over underlying compute behavior | Fine-grained infrastructure tuning is not exposed |
Governance & security | Centralized governance, auditing, and access controls | Governance model tied to Snowflake policies | Multi-platform governance strategies need careful alignment |
Cost efficiency | Efficient for ELT, feature engineering, and batch scoring workloads | Costs scale with Snowflake compute usage | Iterative, long-running workloads may become expensive |
Machine learning workloads | Effective for feature engineering and inference close to data | Not optimized for large-scale distributed training | Deep learning and GPU-heavy workloads may perform better elsewhere |
Ecosystem flexibility | Strong integration with Snowflake-native tools and workflows | Limited access to full open-source Spark ecosystem | Some libraries and advanced frameworks may not be supported |
Snowpark Adoption Guidance: A Phased Approach
Step 1: Identify the right workloads
Begin by selecting workloads where governance, data freshness, and architectural simplicity are most critical. Typical candidates include ELT pipelines, feature engineering, and compliance-sensitive transformations.
Step 2: Run a controlled pilot
Implement Snowpark on non-critical pipelines to validate performance, cost efficiency, and operational impact. This phase helps teams understand execution behavior without introducing business risk.
Step 3: Benchmark and evaluate
Compare Snowpark results against existing platforms or processing engines to establish realistic expectations around performance, scalability, and cost.
Step 4: Expand with confidence
As results stabilize, expand Snowpark usage to additional pipelines and use cases. Standardize design patterns, operational practices, and governance models.
Step 5: Invest in skills and maturity
Develop Snowpark-specific expertise across data engineering and analytics teams to ensure long-term success and sustainable platform adoption.
Use cases where Snowpark excels
Use Case | How Snowpark Adds Value | Business Advantage |
Feature engineering pipelines | Enables feature creation directly on governed, up-to-date data within Snowflake | Improves model accuracy and reduces data movement |
Regulated data transformations | Processes sensitive data in-place without exporting to external platforms | Strengthens compliance and audit readiness |
Batch scoring workflows | Supports large-scale batch inference close to the data source | Faster execution and simplified pipelines |
Internal analytics applications | Allows logic-driven data processing with strong governance controls | Accelerates development while maintaining data integrity |
Compliance-sensitive workloads | Maintains a single source of truth with minimal data duplication | Reduces operational risk and regulatory exposure |
Enterprise ELT pipelines | Orchestrates scalable transformations using Snowflake-native execution | Simplifies architecture and lowers operational overhead |
Final perspective — a global view
For organizations in the USA, Snowpark aligns well with mature cloud environments and increasing regulatory scrutiny. In the UAE and other rapidly digitizing regions, Snowpark supports accelerated transformation by lowering operational complexity and enabling faster delivery of analytics-driven outcomes.
Across global markets, Snowpark represents a shift toward fewer data handoffs, clearer accountability, and tighter alignment between data strategy and business execution.
At Techmango, Snowpark is viewed as a critical enabler for modern data engineering and analytics transformation. Our teams help organizations design Snowpark-ready architectures, migrate existing pipelines, and establish governed, scalable data processing frameworks aligned with enterprise objectives.
By combining deep data engineering expertise with platform-specific best practices, Techmango supports enterprises in realizing the full value of Snowpark—turning unified data platforms into engines for insight, innovation, and measurable business impact.